As described in the context calculation overview, the Statistic functions are designed to provide an easy technique to calculate the basic statistics from the resulting data points in a result set. While these are often done with semantic formulas, they can be much easier to deliver as context logic, because they will change to suit the selections made in a report or visual - which is often more efficient.
- The statistics functions are an extension of the advanced analytic tools described here.
Statistics Logic
The core principal behind statistic calc's is to read all the data points in a query and easily compute basic statistical values. Although these values can be derived in alternative ways (via totals, semantic calculations etc), the key elements driving the math look at the list of items (from a hierarchy) and the selected metric. By changing the hierarchy or the selections, the statistic will change accordingly, without needing to redefine or recode the calculation itself (that is, it is contextual).
However, if the contextual resolution of the statistic logic requires further refinement, it is possible to edit the behavior of the calculation using the Context Calculation Logic Editor.
- Click here to learn about the Context Calculation Logic Editor
Examples
Using the grid below, where we have produced a list of 25 products:
- Standard Deviation: Using a choice of two standard deviations from the sales mean for the products, the lower and upper bound is 30,846 and 567,887 respectively.
- Median: The median (or 50th percentile or "middle" item) in the result set is 282,937.38
- Average: the average for the result set is 299,367.11 (or 7,484,177.64 divide by 25 items)
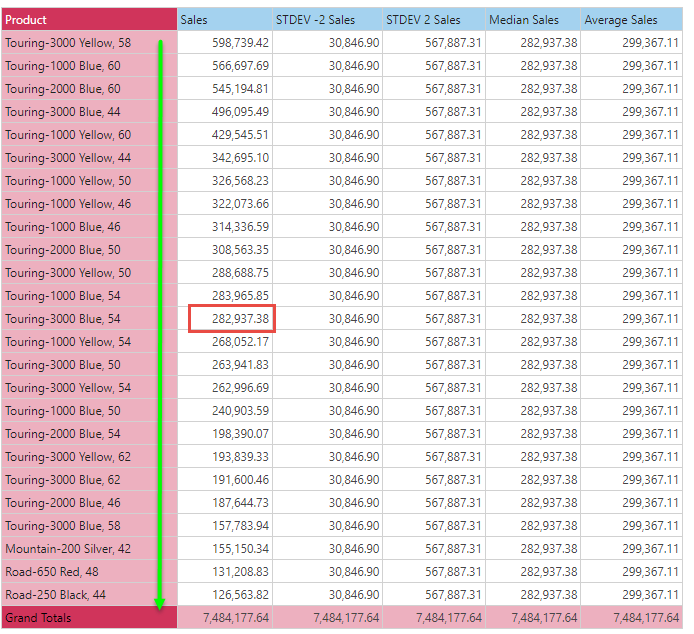
Although it may look strange to create the statistics in example 1 above (they are the same values for the result set, so they are repeated on every row), the applications can be shown in 2 ways:
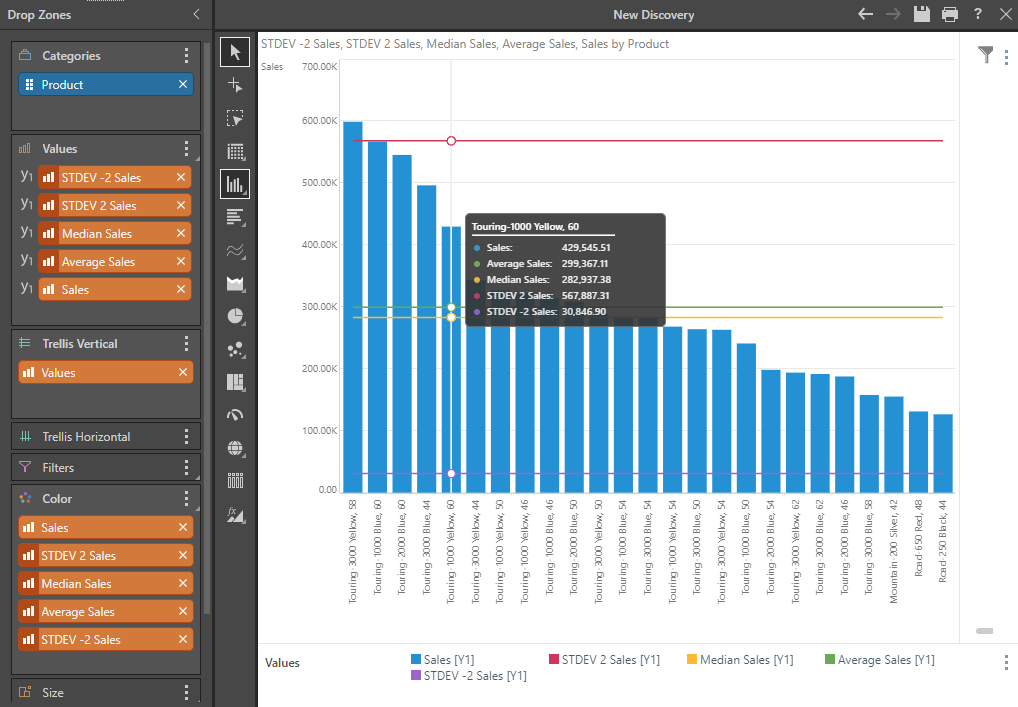
First, we can plot the actual data in a chart (blue bars) and then plot the statistical data along side it (in this case line charts). This is a great way to show how well each point is doing in comparison to the result statistics.
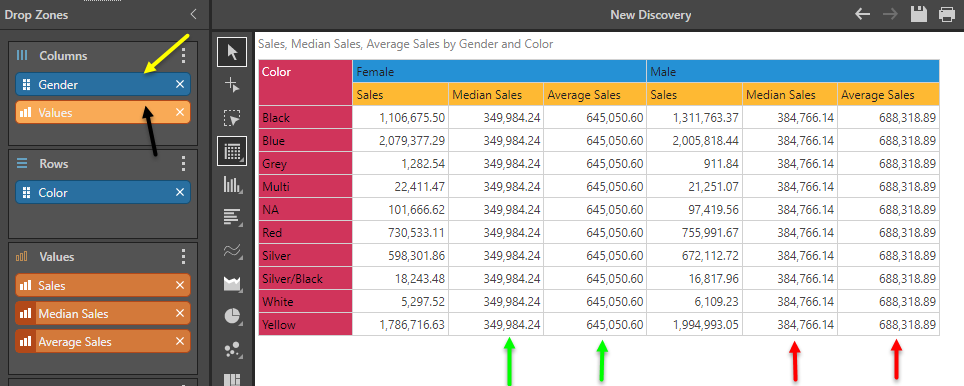
A second use case, it to utilize the value chip placement option (as described here and demonstrated further here) to drive independent statistical values based on other selections made in the query.
In the grid below, we can see sales by color and gender. By putting the values chip on the columns, we can easily see average and median sales amounts for each color set by male and female separately.
Editing Context Calculation Logic
As well as editing and changing the properties of a context calculation, such as its name or format, it is also possible to alter the logic of how the calculation is performed using the Context Calculation Logic Editor.